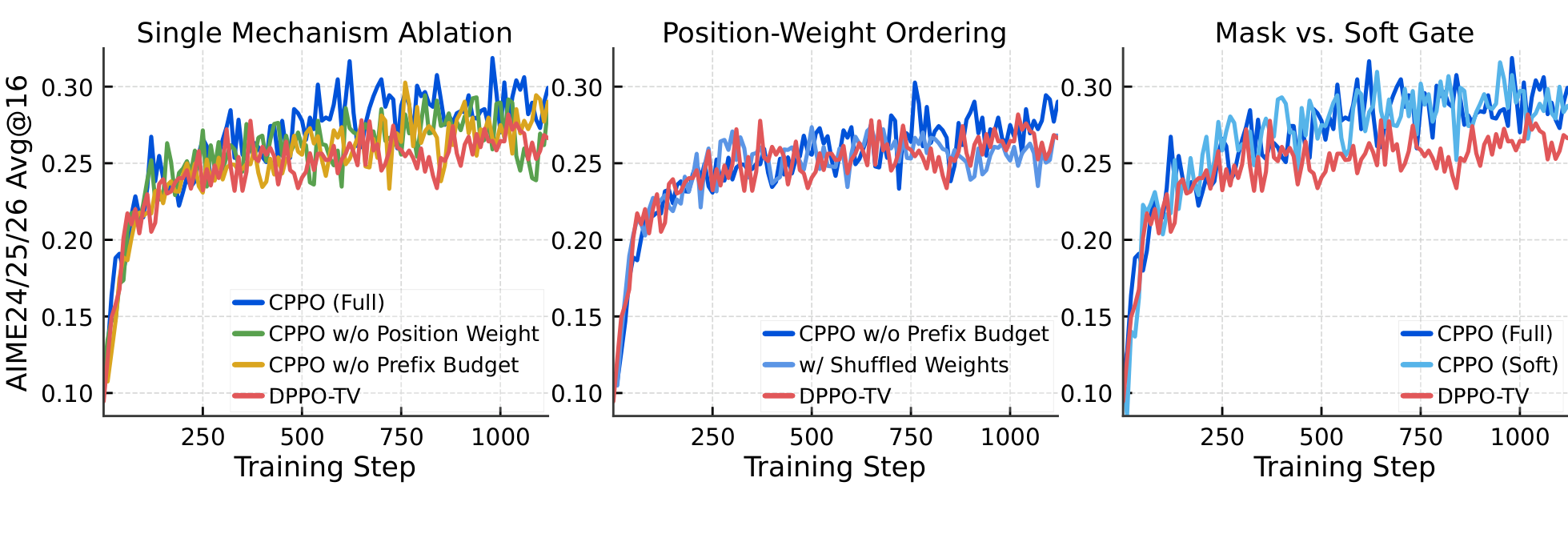
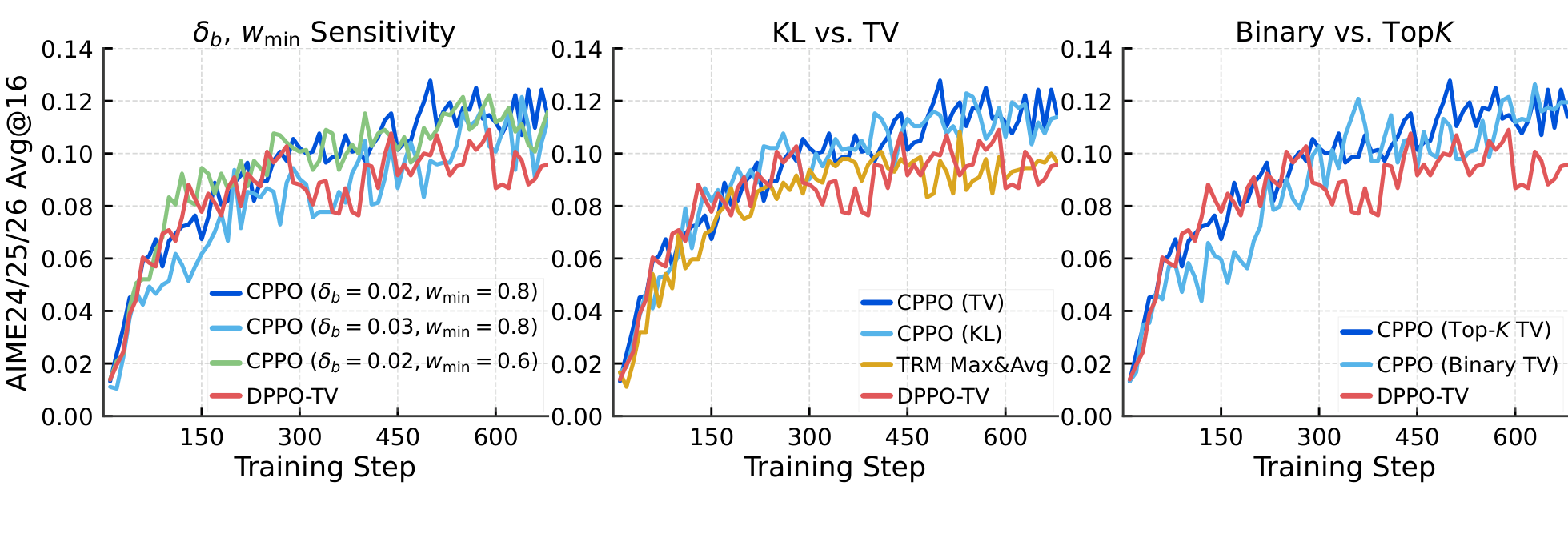
Token Mask & SurrogateToken Mask 与替代目标
The two constraints fold into one feasibility test $I_t$; corrective updates are never blocked, and the mask plugs straight into the PPO/GRPO ratio–advantage objective:
两项约束合并为单一可行性判据 $I_t$;纠正性更新从不被屏蔽,该 mask 可直接嵌入 PPO/GRPO 的 ratio–advantage 目标:
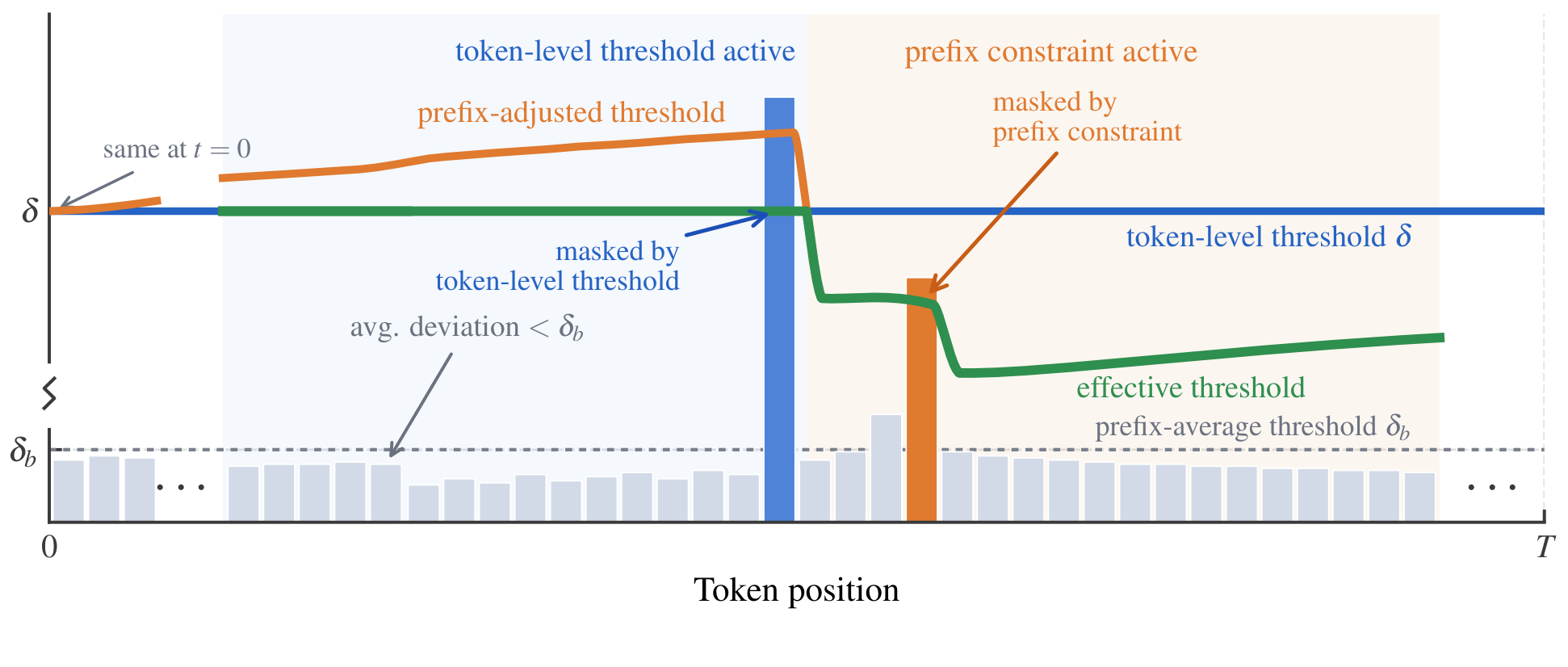
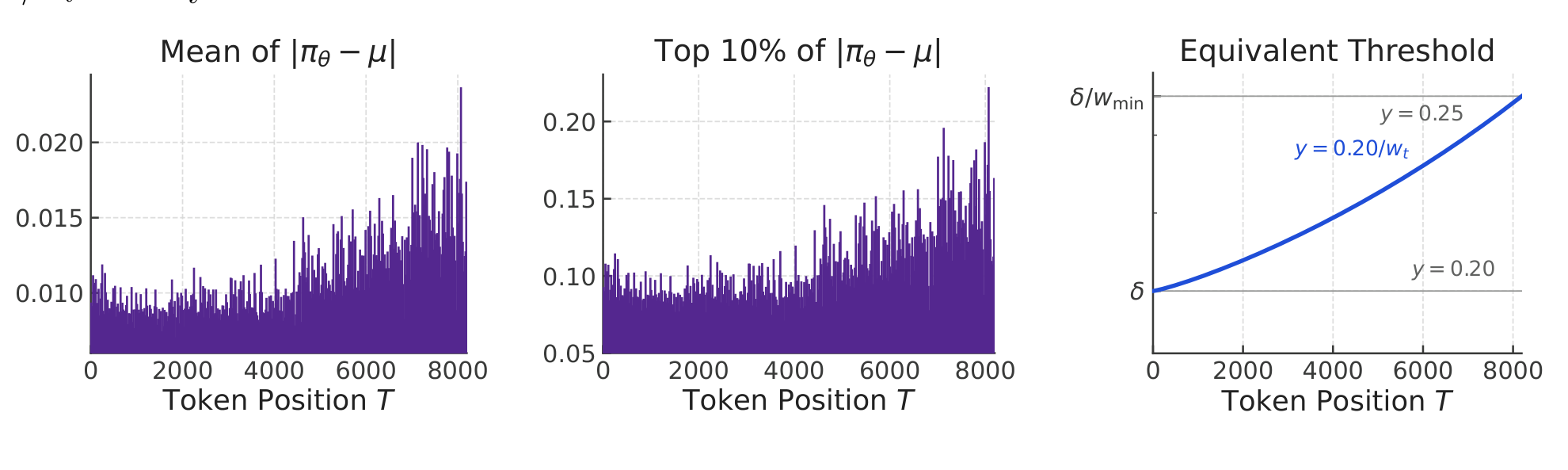
$$M_t^{\text{CPPO}} = \mathbb{1}\!\left(\hat{A}_t(\rho_t-1)\le 0 \;\vee\; I_t\right),\quad I_t : w_t D_t \le \delta \;\wedge\; S_t \le \delta + \delta_b W_{t-1}$$
$$\mathcal{L}^{\text{CPPO}}_{\mu}(\pi) = \mathbb{E}_{\mu}\!\left[\sum_{t=1}^{T} M_t^{\text{CPPO}}\,\rho_t\,\hat{A}_t\right]$$
Reuses the same per-token divergence as DPPO — no extra loss terms, no new estimator.
沿用与 DPPO 相同的逐 token 散度,不增加 loss 项,亦不引入新的估计器。